The resolve-hash command allows to get such URL from a Git hash, or another VCS reference. It can search Phabricator, Gerrit, GitHub and GitLab currently.
Ouf of the box, it will detect your ~/.arcrc configuration and use GitHub public API. You can create a small YAML configuration file it to add Gerrit and GitLab in the mix.
Install it. Use it.
The resolve-hash package is available on PyPI.
$ pip install resolve-hash $ resolve-hash 6411f75775a7aa8db https::⃫github.com/10up/simple-local-avatars/commit/6411f75775a7aa8db2ef097d70b12926018402c1
Specific use cases
Projects moved from GitHub to GitLab
GitLab requires any query to the search API to be authenticated. You can generate a personal access token in your user settings; the API scope is enough, so check only read_api.
Then you can add create a $HOME/.config/resolve-hash.conf file with the following content:
# GitLab gitlab_public_token: glpat-sometoken
For Wikimedia contributors
Gerrit exposes a REST API. To use it, create a $HOME/.config/resolve-hash.conf file with the following content:
# Gerrit REST API gerrit: - https://gerrit.wikimedia.org/r/
Gerrit will be then queried before GitHub:
$ resolve-hash 311d17f289470 https::⃫gerrit.wikimedia.org/r/c/mediawiki/core/+/768149
Note if you’ve configured Arcanist to interact with phabricator.wikimedia.org, your configuration in ~/.arcrc is used BEFORE the Gerrit one. Tell me if you’re in that case, we’ll allow to order resolution strategies.
What inspired this project?
Terminator allows plugins to improve the behavior of the terminal. Some plugins allows to expressions like Bug:1234 to offer a link to the relevant bug tracker.
What if we can detect hashes, especially VCS hashes, to offer a link to the code review system, like Phabricator or Gerrit, or at least to a public code hosting facility like GitHub?
What’s next?
We can add support for private instances of GitHub Enterprise and GitLab. Code I wrote in VCS package is already ready to accept any GitHub or GitLab URL, and is so prepared to accept a specific instance, so it’s a matter of declare new configuration options and add the wrapper code in VcsHashSearch class.
A cache would be useful to speed up the process. Hashes are stable enough for that.
Write a Terminator plugin, so we solve the root problem described above.
The code is extensible enough to search other kind of hashes than commits, but I’m not sure we’ve reliable sources of hashes for know files or packages.
References
- Nasqueron DevCentral
- Python package repository
Thanks to all the people whom I’ve met or I’ve been engaged with during this year for these contributions.
]]>
Since MediaWiki 1.16, the software has supported — as an option — RDFa and Microdata HTML semantic attributes.
This commit, integrated to the next release on MediaWiki, 1.27, will embrace more the semantic Web making these attributes always available.
If you wish to use it today, this is already available in our Git repository.
This also simplify slightly the cyclomatic complexity of our parser sanitizer code.
Microdata support will so be available on Wikipedia Thursday, 24 March 2016 and on other projects Thursday, 23 March 2016.
If you already use RDFa today on MediaWiki
First, we would be happy to get feedback, as we’re currently considering an update to RDFa 1.1 and we would like to know who is still in favour to keep RDFa 1.0.
Secondly, there is a small effort of configuration to do: open the source code of your wiki and look the <html> tag.
Copy the content of the version attribute: you should see something like like <html version=HTML+RDFa 1.0">.
Now, edit InitialiseSettings.php (or your wiki farm configuration) and set the $wgHtml5Version setting. For example here, this would be:
$wgHtml5Version="=HTML+RDFa 1.0";
For the microdata, there is nothing special to do.
]]>
AI
What if instead to understand how the brain works, we copy the neural connections as is? This is what the OpenWorm project tries to do with C. elegans. And, big surprise, that works and allows a bot to move.
Wikipedia
An infographics of the locality of Wikipedia participants shows without any surprise they are mainly from Europe and North America.
If you’re into dumps, the Wikipedia / MediaWiki XML dump grepper will help you to find a particular piece of data, like the text of one article.
Tools
Dev / search. The silver searcher, ag, offers a faster approach than ack to search your code.
Fun / autogenerator. Some years ago, cgMusic offered an implementation on how a computer program could create music. Add some image generation techniques and a word generators, and you can have a fake music generator offering full albums. Ælfgar has stumbled upon Liquified Death by Income Yield.
GIS. Turf is a new open source JavaScript GIS library. This post explains the capabilities and features, including its great offline support.
Electronics
What if an Arduino embeds a web server and allows programmation from the web browser? This is exactly what the Photon by Spark does.
Quartz
An infographics showing satellites orbiting Earth and a point of view of the Uber economy.
Literature
The GoT series offer some comprehensive scenes of torture. Did you ask yourself their interest or need for the plot? Marie Brennan offers a great opinion in « Welcome to the Desert of the Real ».
]]>November is the Philae landing on the Comet Churyumov-Gerasimenko month and the ESA photo release under CC-BY-SA (one of them here) month. Mainly DevOps links in this post, a Wikidata tool and an algorithm visualisation.

ESA/Rosetta/NAVCAM, CC-BY-SA 3.0 IGO
Dev
Craft. Jeroen de Dauw has prepared interesting slides about clean functions. Your function should do one task, not be a class disguised in procedural code.
Raft. In a distributed environment, how do you achieve a similar state? Raft is an answer to this question, as a distributed consensus algorithm. To understand how it works, The Secret Lives of Data offers a visual guide.
Wikidata
Wikidata no labels. Harmonia Amanda and Hsarrazin wanted to find items without labels in French, respectively about the Tolkien’s Legendarium or Russians persons to translate. This tool allows you to get some Wikidata items through a WDQ query or to encode them directly, and print a table with the part of these items without label in the specified language.
DevOps
Once upon a time there were a Linux theme park. As a Cobbler / SpaceWalk alternative, we start to see new software to appear: katello/foreman. It’s a part of Katello, the upstream of Satellite 6, and a replacement for SpaceWalk. You want to dive into the Linux theme park? Build images, deploy, manage resources? You’ll be served. Thank you to jnix for these software recommendation.
And now, near the sea. ShipYard allows you to manage Docker instances and containers.
But what is more interesting is the alpha release of OpenShift Origin, the third generation of OpenShift, with a new system design. It relies on Docker and the following technologies:
- Kubernetes, an active controller to orchestrate and ensure the desired state of the containers;
- An etcd server (which uses the Raft algorithm described above);
With that concepts, you’re ready for the introduction hands-on tutorial available.
The puppetmaster becomes old. Ryan Lane, formerly in Wikimedia ops team, blogged this summer about a Puppet alternative at his new job: Moving away from Puppet: SaltStack or Ansible? For Ryan, 10K+ lines of Puppet codes is now only 1K of SaltStack or Ansible code. The winner of their test to port the Puppet infrastructure into both is SaltStack. It’s a pity, I would have loved to merge yet another fictional universe into the Nasqueron project and add the Ursula K. Guin ansible in the mix.
Sysadmin
FreeBSD 10.1. The first new version of FreeBSD after the SSL bugs is out, and will immediately be deployed on Ysul and Sirius machines as test. Bhyve can use a pure ZFS filesystem and UDP-Lite protocol is finally here.
]]>In the servers world
SSL. October is the month we disabled SSLv3 protocol support from nginx following the POODLE attack. So this means we can look to this paper, nginx configuration and a tool to check SSL configuration. The provider Linode has published a comprehensive guide to mitigate the attack.
FreeBSD. FreeBSD 10.1-RELEASE will soon be available. The virtual terminal console driver vt is improved. Oh, and you can now boot bhybe on ZFS. Shell servers will have to deal with the fact login.conf settings will take precedence on .profile and other shell environment for variables like path, blocksize or umask.
Docker. To improve Docker workflow, nitrous.io has released tug, a set of scripts in Go to help common tasks.
Thus shall ye compile in JavaScript
Humble Bundle launches the Humble Mozilla Bundle, games compiled in ASM.js and so playable in the browser.
Meanwhile, in the functionnal language world, a paper shows you can compile OCaml in JS, an it’s sometimes quicker in the JS JIT than it its own JIT (but well… you can also compile OCaml in native, and OCaml JIT isn’t really well optimized).
So if you want to respect this commandment, just compile your C code with clang: emscripten will then happily compile your LLVM bytecode in ASM.js.
Gamergate / NotYourShield
A CNN journalist reads the gamergate as the end of the narration controlled by journalists.
When an Examiner journalist suggests #NotYourShield is 4chan white heterosexual users posing as women and PoC, his tweet is replied with a lot of photos from women and PoC. We so now have a picture of the diversity in video games (permanent link).
{kind=link}
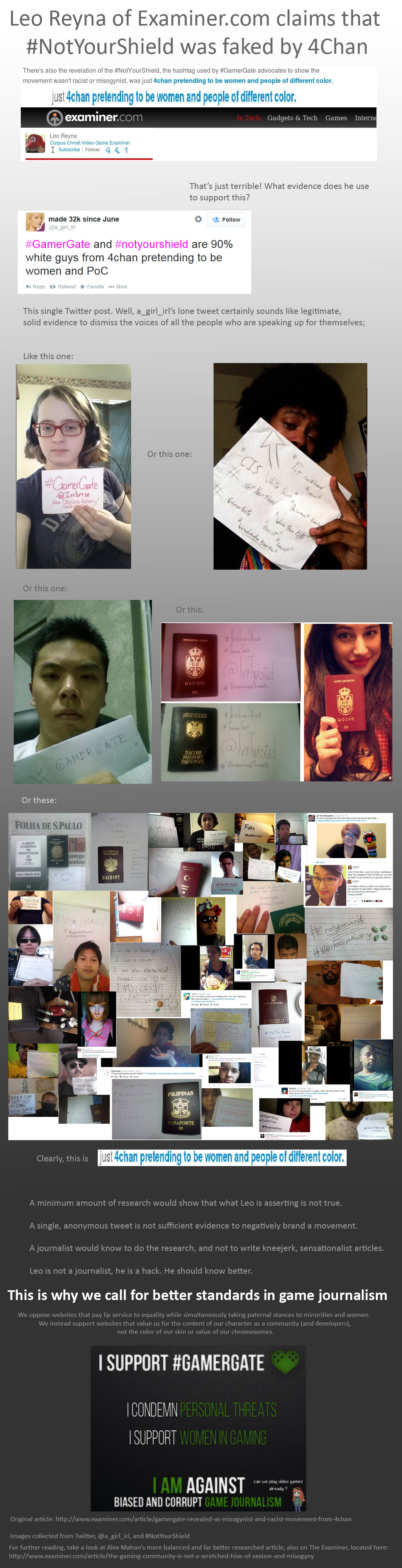{kind=link}
On a related theme, I Can Tolerate Anything Except The Outgroup is interesting to read and heavily commented.
Finally, a call for help:
I have a new project, but I need your help. Looking for diverse female voices in STEM that could donate their time & expertise.
— Randi Actually (@freebsdgirl) October 20, 2014
Curiosities
Some scientists push to a new definition of planet, to take in account exoplanets. In such a definition, Pluto would be again a planet. Harvard organized a debate, this position wins.
At Databricks, they carved this pumpkin for halloween:
Carved something scary into pumpkin cc/ @jamesiry @databricks (office jackolantern) pic.twitter.com/sqiNaYGDQy
— Heather Miller (@heathercmiller) October 27, 2014
… this is the amount of English wikipedia contributors allowed to participate to the 2013 2013 Arbitration Committee Elections.
The eligibility condition checked by this number is the amount of accounts having made at least 150 mainspace edits by 1 November 2013.
The English Wikipedia has now 12 years. This figure so means there is something like ten thousands contributors having made a significant contribution to the main namespace each year, a little less than 1 000 per month, at least one per hour.
If the English Wikipedia would be a country, and those people its population, it would the 192th according this list of countries by population. This is something between Jersey or the United States Virgin Islands, and Guam.
Thank you to Ælfgar for this country comparison idea.
]]>- You have a nginx webserver
- You have several MediaWiki installation on this server
- You would like to have a simple and clear configuration
Solution
You want a configuration file you can include in every server {} block MediaWiki is available
Implementation
- Create a includes subdirectory in your nginx configuration directory (by default, /usr/local/etc/nginx or /etc/nginx).
This directory can welcome every configuration block you don’t want to repeat in each server block. - You put in this directory mediawiki-root.conf, mediawiki-wiki.conf or your own configuration block.
- In each server block, you can now add the following line:
Include includes/mediawiki-root.conf;
Configuration I – MediaWiki in the root web directory, /article path
This is mediawiki-root.conf on my server:
# Common settings for a wiki powered by MediaWiki with the following configuration:
# (1) MediaWiki is installed in $root folder
# (2) Article path is /<title>
# (3) LocalSettings.php contains $wgArticlePath = "/$1"; $wgUsePathInfo = true;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location ~ ^/images/thumb/(archive/)?[0-9a-f]/[0-9a-f][0-9a-f]/([^/]+)/([0-9]+)px-.*$ {
#Note: this doesn't work with InstantCommons.
if (!-f $request_filename) {
rewrite ^/images/thumb/[0-9a-f]/[0-9a-f][0-9a-f]/([^/]+)/([0-9]+)px-.*$ /thumb.php?f=$1&width=$2;
rewrite ^/images/thumb/archive/[0-9a-f]/[0-9a-f][0-9a-f]/([^/]+)/([0-9]+)px-.*$ /thumb.php?f=$1&width=$2&archived=1;
}
}
location /images/deleted { deny all; }
location /cache { deny all; }
location /languages { deny all; }
location /maintenance { deny all; }
location /serialized { deny all; }
location ~ /.(svn|git)(/|$) { deny all; }
location ~ /.ht { deny all; }
location /mw-config { deny all; }Configuration II – MediaWiki in the /w directory, /wiki/article path
This is mediawiki-wiki.conf on my server:
# Common settings for a wiki powered by MediaWiki with the following configuration:
# (1) MediaWiki is installed in $root/w folder
# (2) Article path is /wiki/<title>
# (3) LocalSettings.php contains $wgArticlePath = "/wiki/$1"; $wgUsePathInfo = true;
location /wiki {
try_files $uri $uri/ /w/index.php?$query_string;
}
location ~ ^/w/images/thumb/(archive/)?[0-9a-f]/[0-9a-f][0-9a-f]/([^/]+)/([0-9]+)px-.*$ {
#Note: this doesn't work with InstantCommons.
if (!-f $request_filename) {
rewrite ^/w/images/thumb/[0-9a-f]/[0-9a-f][0-9a-f]/([^/]+)/([0-9]+)px-.*$ /w/thumb.php?f=$1&width=$2;
rewrite ^/w/images/thumb/archive/[0-9a-f]/[0-9a-f][0-9a-f]/([^/]+)/([0-9]+)px-.*$ /w/thumb.php?f=$1&width=$2&archived=1;
}
}
location /w/images/deleted { deny all; }
location /w/cache { deny all; }
location /w/languages { deny all; }
location /w/maintenance { deny all; }
location /w/serialized { deny all; }
location ~ /.(svn|git)(/|$) { deny all; }
location ~ /.ht { deny all; }
location /w/mw-config { deny all; }Example of use
www.wolfplex.org serves other application is subdirectories and MediaWiki for /wiki URLs.
This server block:
- is a regular one
- includes our includes/mediawiki-wiki.conf configuration file (scenario II)
- contains a regular php-fpm block
- contains other instructions
server {
listen 80;
server_name www.wolfplex.org
access_log /var/log/www/wolfplex.org/www-access.log main;
error_log /var/log/www/wolfplex.org/www-error.log;
root /var/wwwroot/wolfplex.org/www;
index index.html index.php index.htm;
[...]
include includes/mediawiki-wiki.conf;
location / {
#Link to the most relevant page to present the project
rewrite /presentation/?$ /w/index.php?title=Presentation last;
#Link to the most relevant page for bulletin/news information:
rewrite /b/?$ /w/index.php?title=Bulletin:Main last;
[...]
}
[...]
location ~ \.php$ {
try_files $uri =404;
fastcgi_pass 127.0.0.1:9010;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}Some notes
- Configuration is based on Daniel Friesen’s MediaWiki Short URL Builder, who collected various working nginx ones. There are some differences in the rewrite, our goal here is to have a generic configuration totally agnostic of the way .php files are handled.
- Our configuration (not the one generated by the builder) uses a if for the thumbnails handler. The nginx culture is a culture where you should try something else than an if. See this nginx wiki page and this post about the location if way of work for more information.
Cody Lundquist, an Australian from Sidney, created a 8 bit music audio library built on the top of the Web Audio API, called 8Bit.js Audio Library.
You define a time (e.g. 4/4), a tempo, and you then the notes.
Submitted 2 days on Reddit, the library got a favorable reception, with some people adapting themes. There is even an original composition, rather nice, called Cities.
A LilyPond support is planned, so in the future there could be a possibility to implement this library into the MediaWiki score extension.
Not yet for every browser
- Safari 6 supports it, so only on iOS and Mac, not yet on Windows.
- Chrome 10+ supports it, and so Opera 15,
- Firefox, Internet Explorer and Opera 12 don’t support it.
[2020 edit: Firefox has added support for it in versions 25 (desktop) and 26 (mobile)]
Links
- Listen to Tetris with 8Bit.js
- 8-bit music on Wikipedia
- Web Audio API specifications
- AngularJS, the framework used by 8Bit.js
- Apple documentation about the Web Audio API
- Coming soon support on Firefox
Acknowledgment
Thanks to Linedwell for the help during browsers test.
]]>Activity feeds will be timelines to offer these views;
- What are the users’ last activities (commits, patchsets, merges) on Gerrit?
- What’s going on on the
mediawiki/extensions/SemanticMediaWikirepository?
Here the homepage dashboard:

And here the wireframe of the project activity feed:

About the design
This code is built on the top of Foundation, a responsive CSS framework. This allows to provide a smooth experience for your phone or tablet: columns will collapse into a more linear view if resolution width is narrow.
Avatars uses Gravatar. When an user doesn’t have a Gravatar account, identicons are used.
About the infrastructure and code
A Node service acts as proxy, and mirrors the Gerrit events stream, so it’s available to any simple TCP connexion instead to require a SSH connection.
I’ll provide access to this Node server to the community, so any tool with socket and JSON support with be able to interact with Gerrit events. If you’ve a need for a push model, ie to post notifications, please let me know the format and I will take care of that.
Then, a script reads the stream and write the XML feeds. It also monitors the Node -> SSH connection, to relaunch the service if needed (e.g. if the Jenkins server is rebooted). These XML feeds are publicly accessible, so you can also create a service based on them.
Finally, XSLT will be used to render these feeds in HTML and RSS documents. That’s for the humans and the most generic tools..
It will be at this moment time to take care of special needs, like combined feeds for Google Summer of Code or the Outreach Program for Women.
What do you think of this and do you need?
Please tell me what you think of this tool, and what you would like to find on this tool.
We also need a cool name for the application.
]]>